동영상에서 하드 코딩된 자막을 추출하여 다른 언어로 번역하기
*동영상의 자막이 자막 파일이 없이 동영상에 합치된 경우가 있다. 그것을 하드코딩되었다고 하는데 그런 경우에 OCR 기능을 사용하여 자막을 추출하는 방법을 알아보자. 그리고 자막을 다른 언어로 번역된 자막으로 자막 파일을 만드는 방법도 함께 알아보자.
(1) 다음 링크에서 Video Sub Finder를 다운로드한 후, 임의의 폴더에 압축을 푼다.

(3) File > Open Video 메뉴에서 자막을 추출할 동영상 파일을 불러온다.
(4) 영어로 된 자막을 추출하기 위해 가로선을 정확히 영어자막에 위치시킨다. 자막이 가로선을 벗어나게 해서는 안된다.

(5) 동영상을 처음으로 위치시킨 후 하단에 'Run Search' 버튼을 클릭한다. 그러면 동영상 내에서 추출할 자막을 검색하는데 동영상의 처음부터 끝까지 실행시켜야 한다.

(6) 'Run Search' 기능이 종료되었으면 'OCR' 탭을 열고 'Create Cleared Text Images' 버튼을 클릭한다. 그러면 추출된 파일의 이미지가 'TXTImages' 폴더에 저장된다.

(7) 'Text Images' 폴더의 추출된 Text Image는 다음과 같은 형태로 저장된다.

(8) 다음 링크에서 Subtile edit를 다운로드하여 설치한다.
위치 : https://github.com/SubtitleEdit/subtitleedit/releases
(9) '파일 > 가져오기 > 이미지에서' 메뉴를 클릭하면 다음과 같은 창이 뜬다. 오른쪽 상단의 점 버튼을 클릭하여 'Text Images' 폴더의 파일을 모두 불러들인다.
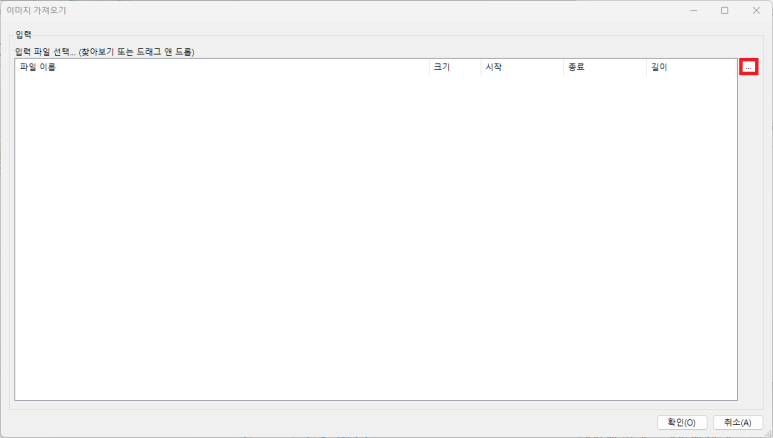
(10) '이미지 가져오기' 창에 불러들인 화면은 다음과 같다.

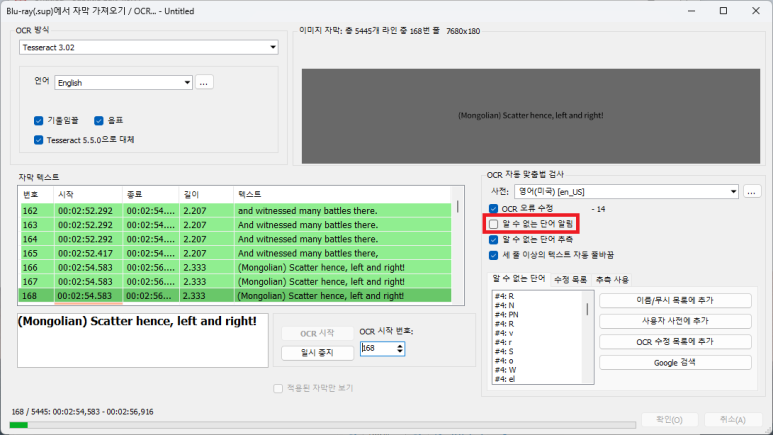
(11) 다음 창에서 'OCR 방식'을 선택한 다음 언어를 'English'로 한 후 'OCR 시작' 버튼을 클릭한다.
*Tesseract 3.02는 이미지의 인식률이 높지 않고 속도가 느리다. 다른 OCR 방식을 선택해야 한다고 본다. *'Goggle Cloud Vision API를 통한 OCR'은 매우 빠르고 인식율도 높지만 3개월 동안만 무료로 사용이 가능하다.

(12) 자동으로 OCR 인식이 계속 되게 하려려면 '알 수 없는 단어 알림' 옵션을 제거한다.
(13) 다음으로 자동 자막 번역 기능에 대해 알아보자. 먼저 영어로 된 자막 파일을 '파일 > 열기' 메뉴를 클릭하여 불러온다.

(14) '번역 > 자동 번역' 메뉴를 클릭하면 다음과 같은 창이 뜬다.
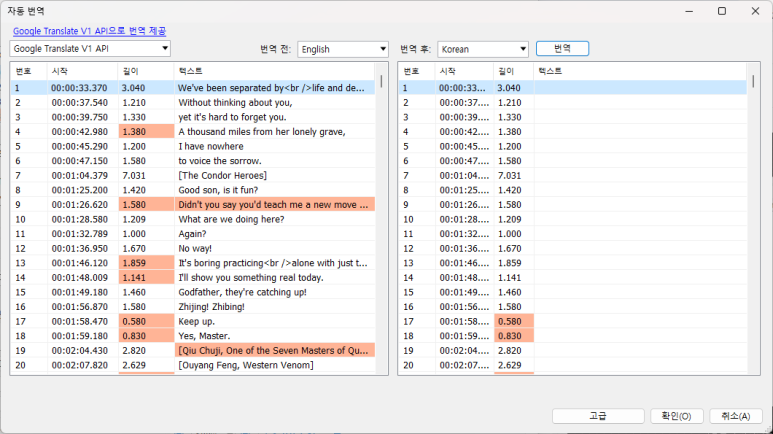
(15) 번역 엔진을 선택한 다음 '번역 전'을 'English'로 하고 '번역 후'를 'Korean'으로 하면 영어에서 한글로 번역된 자막이 생성된다.
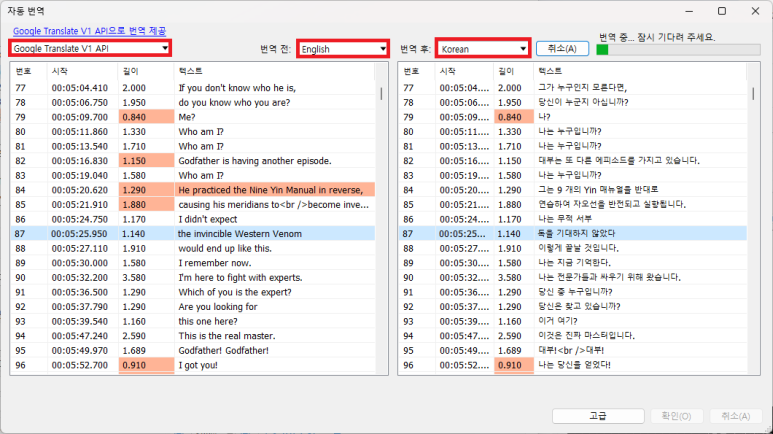
(16) '파일 > 저장' 메뉴를 클릭하면 한글로 번역된 자막파일이 폴더에 저장된다. 동영상과 자막 파일을 같은 폴더에 놓고 이름을 일치시키면 한글로 번역된 자막을 동영상에서 볼 수 있다.
